面对多格式、高维度的科学数据,传统检索与分析模式已难以满足高效科研需求。近日,πFlow凭借其多模态文档解析能力,支撑ScienceDB AI平台实现从“文件检索”到“内容问答”的范式跃迁。科研人员可直接使用自然语言,对平台内数据集内容进行在线提问并即时获取精准洞察,大幅降低科研数据应用门槛,加速科研决策进程。
从“看懂格式”到“理解内容”
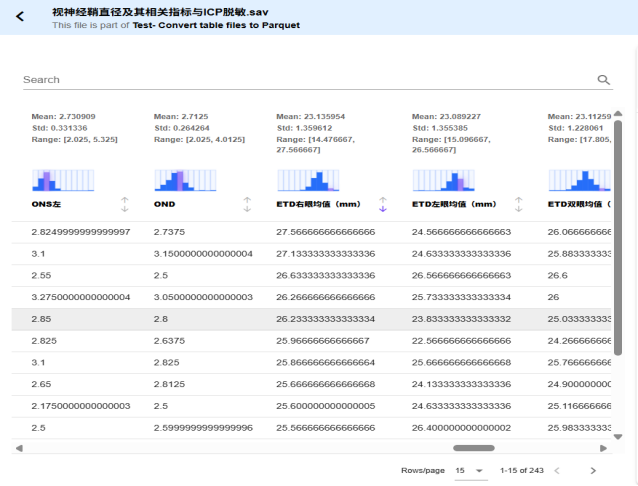
πFlow多模态数据解析器如同一位“全能数据翻译官”,能够将科学数据文件智能转化为易于AI大模型理解和分析的标准化格式(Parquet/Arrow/Markdown)。目前,该解析器已覆盖HDF5、PDF、CSV、TSV、SAV、TAB、ODS、XLS/XLSX、PPTX及DOCX等16类高频格式,并已成功处理超过16.6万个数据文件。
从“描述统计”到“深度洞察”
解析不止于格式转换,更在于深度理解。πFlow可对数据中的8种核心数据类型(如数值、文本、类别、时间序列等)进行自动化特征提取与统计,生成涵盖空值分析、分布直方图、频率统计等12大类特征的标准化报告。这意味着,系统不仅能回答“数据在哪里”,更能解读“数据说明了什么”。例如,针对一份数据文件中的float类型温度字段,πFlow可自动分析其数据的完整性(如空值占比)、波动范围(最大值、最小值)、集中趋势(平均值、中位数)以及整体分布形态(直方图参数),从而迅速回答诸如“该地区夏季温度的典型范围与分布特征是什么”等问题。
关于πFlow
πFlow(原名PiFlow)是中国科学院计算机网络信息中心团队自主研发的科学数据流水线处理与调度系统,入选首批木兰开源社区孵化项目。该系统将科学数据采集、清洗、处理、存储与分析进行抽象和组件化开发,以所见即所得、拖拽配置的高效方式实现大数据处理流程化配置、运行与智能监控。支持算子即插即用,目前已集成基础通用、空间、天文、生态、青藏高原、农业等领域算子超过280个。具备亿级数据的ETL处理能力,经测试较Apache NiFi平均性能提升5倍以上。目前已规模化支撑12个国家科学数据中心、52个野外台站的数据加工,并孵化7个领域专用数据加工软件,同时支撑科技、工业、医疗健康等多领域软件工程案例。