新功能速递
近日,科学数据银行(ScienceDB)正式实现对Croissant协议的支持。这一重要升级将显著提升科学数据的标准化管理与机器学习(ML)场景的适配能力,提升数据的AI-Ready水平,为全球科研人员及开发者提供更高效、更智能的数据共享与应用服务。
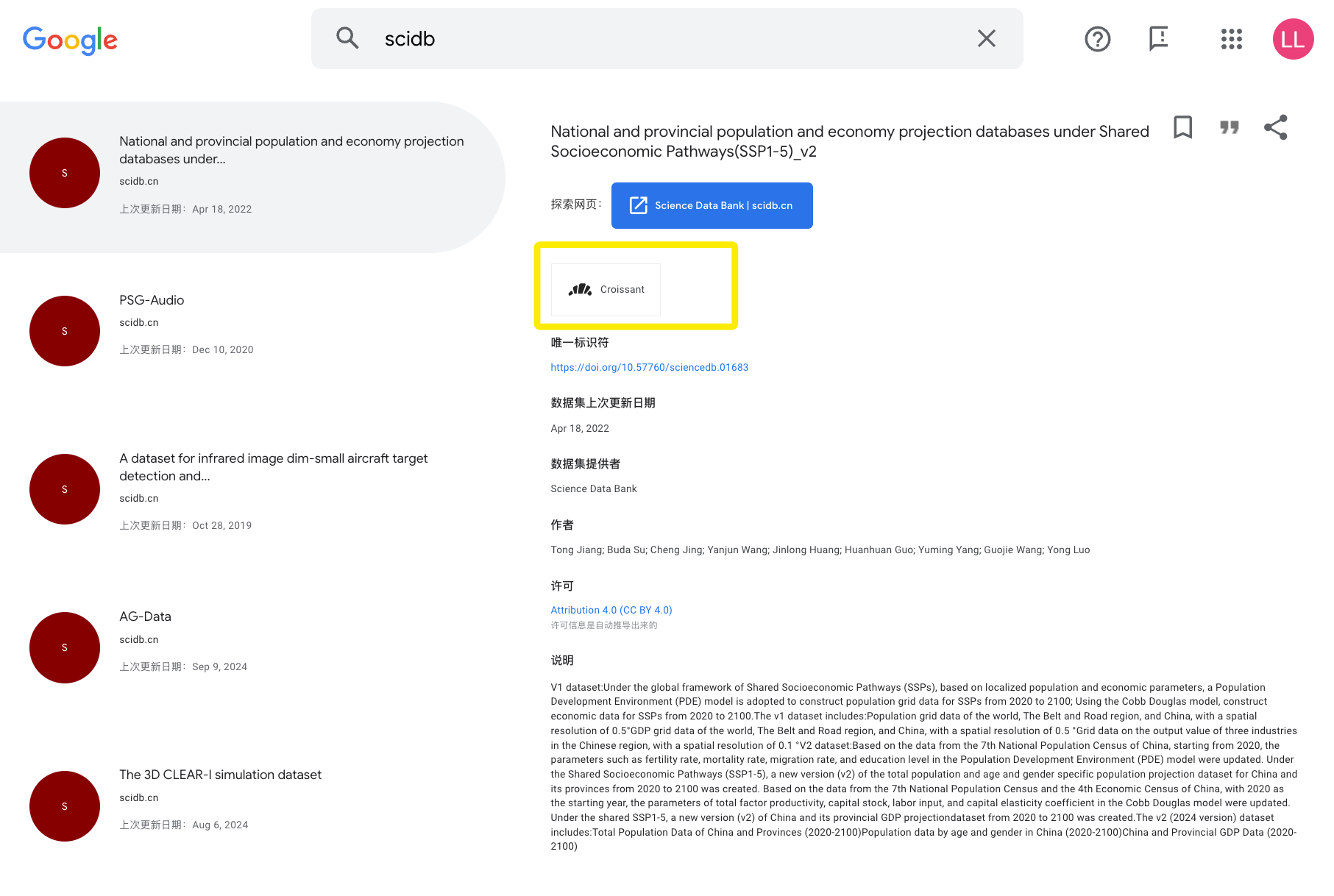
图1 ScienceDB的Croissant协议认证和收录情况
Croissant协议:机器学习数据标准化的“密钥”
Croissant是一种专为机器学习设计的元数据格式,通过整合数据集的元信息、资源描述、结构定义及ML语义,以JSON-LD格式实现数据的标准化表达。其核心目标是为复杂的数据集提供统一的“语言”,从而简化数据发现、清洗和模型训练流程。例如,用户可通过Croissant文件快速定位数据集中的特征字段、定义训练/测试集划分,甚至指定数据在特定任务(如NLP或计算机视觉)中的用途。
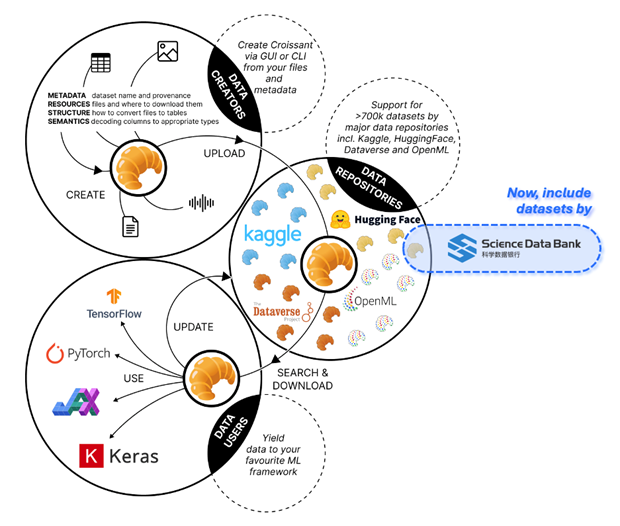
图2 Croissant协议的ML框架支持情况
( 原始图出自参考文献[1] )
ScienceDB的Croissant赋能:三大功能升级
1.全栈机器学习框架无缝支持
ScienceDB集成Croissant后,用户可直接将平台内存储的数据集加载至主流ML框架(如TensorFlow、PyTorch、JAX等),无需额外格式转换。例如,通过TensorFlow Datasets的CroissantBuilder工具,开发者仅需指定Croissant文件的URL即可自动构建数据集管道,显著缩短模型开发周期。此外,Hugging Face和Kaggle等平台已原生支持Croissant,进一步扩大了ScienceDB数据的应用生态。
2. 细粒度数据描述与可追溯性
传统数据共享常面临元数据缺失或描述模糊的问题。通过Croissant协议,ScienceDB新增了对数据内容的精细化描述能力。
3. 跨平台互操作性与数据发现效率提升
ScienceDB的Croissant文件支持嵌入Schema.org标准,可被Google数据集搜索等工具索引,使数据更易被全球研究者发现。同时,平台与国际学术出版商(如Springer Nature)的合作进一步增强了数据的可信度与引用价值。
未来计划
平台目前实现了二维表格类型文件内容的Recordsets生成,本年度将上线AI-Ready编辑器,辅助作者进行其他类型文件和RAI(Responsible AI)内容的编辑,支持自定义的羊角包协议生成。
参考文献:
[1] Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Pieter Gijsbers, Joan Giner-Miguelez, Nitisha Jain, Michael Kuchnik, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Pierre Ruyssen, Rajat Shinde, Elena Simperl, Goeffry Thomas, Slava Tykhonov, Joaquin Vanschoren, Jos van der Velde, Steffen Vogler, and Carole-Jean Wu. 2024. Croissant: A Metadata Format for ML-Ready Datasets. In Proceedings of the Eighth Workshop on Data Management for End-to-End Machine Learning (DEEM '24). Association for Computing Machinery, New York, NY, USA, 1–6. https://doi.org/10.1145/3650203.3663326