大数据流水线处理与调度系统 πFlow V1.9版本正式发布,本次更新包含以下内容:
1.新增可视化功能;
2.新增Python基础镜像管理模块;
3.新增Chroma、Faiss、Weaviate、Pinecone、Qdrant向量数据库存储组件。
新增可视化功能
【数据可视化】支持用户在【数据库配置】模块配置数据库的数据源,也可以在【数据源配置】模块手动上传Excel数据作为数据源,然后在【可视化配置】模块中,用户可以选择已配置的数据源,进行直观的数据展示与可视化分析。支持两种类型的数据源:Mysql和Excel。
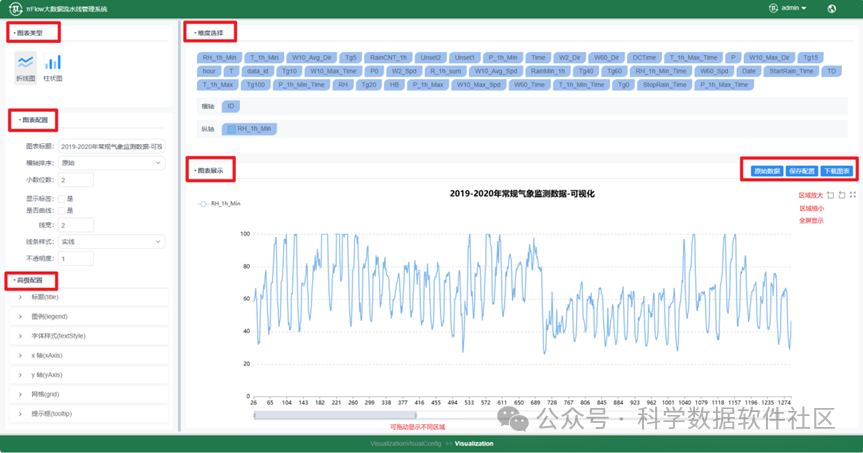
可视化页面功能丰富,你可以自由配置,实现想要的可视化效果。左侧支持折线图和柱状图两种图标类型,支持对图表的标题、横轴排序、小数位数、线宽、不透明度等进行配置,还支持对标题、图例、字体样式、x轴、y轴、网格和提示框的高级配置。“维度选择”列举了可视化数据的所有Schema,你可以拖动选择列作为横轴和纵轴。选择横轴和纵轴后,“图表展示”处可展示数据,下方的滚轮可以拖动显示不同的区域,右侧的“区域放大”、“区域缩小”和“全屏显示”也支持对显示区域进行控制。支持查看“原始数据”,“保存配置”,如果你得到了一张不错的可视化图表,可以点击“下载图表”将图表保存。
新增Python基础镜像管理模块
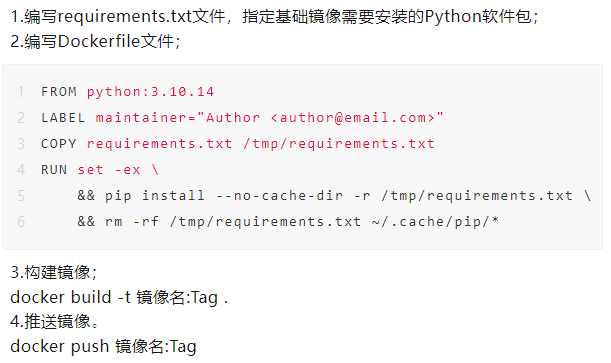
为解决Python组件镜像构建耗时较长的问题,πFlow新增基础镜像管理功能,用户可以提前构建好组件的基础镜像并上传,然后关联组件即可。下面举例说明一下如何构建基础镜像。
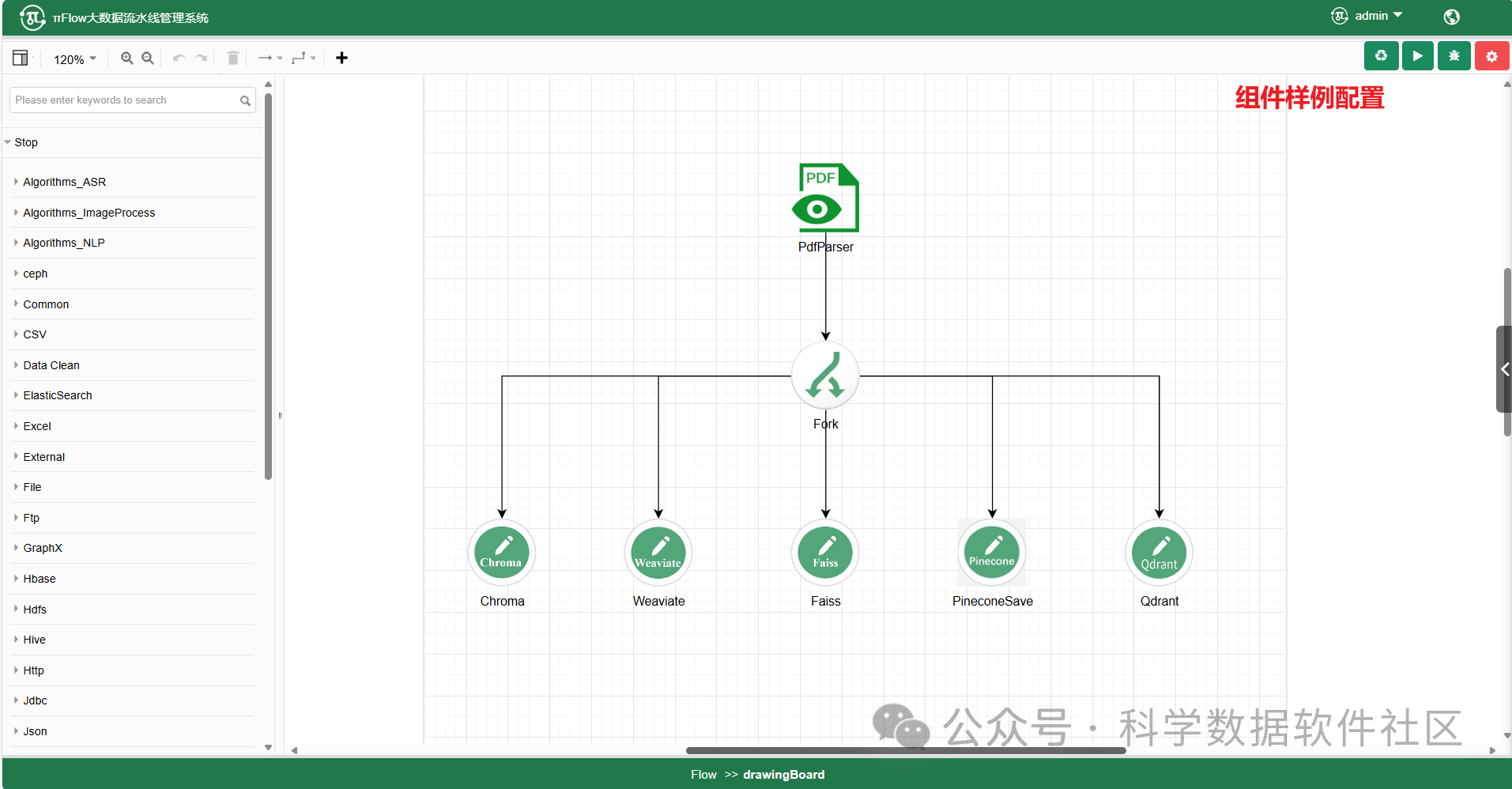
新增Chroma、Fais等向量数据库存储组件
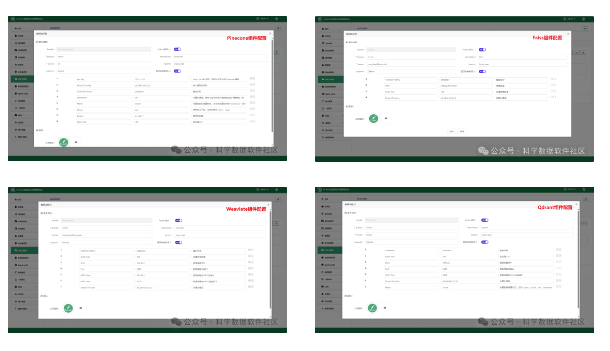
πFlow新增Chroma、Faiss、Weaviate、Pinecone、Qdrant向量数据库存储组件,旨在将PdfParser、ImageParser等非结构化数据解析组件的输出数据向量化后存储到主流的开源向量数据库中。组件支持通过不同的嵌入模型进行向量化处理,并提供高效的存储方案,以满足大规模数据(如用于大模型训练)的存储需求。 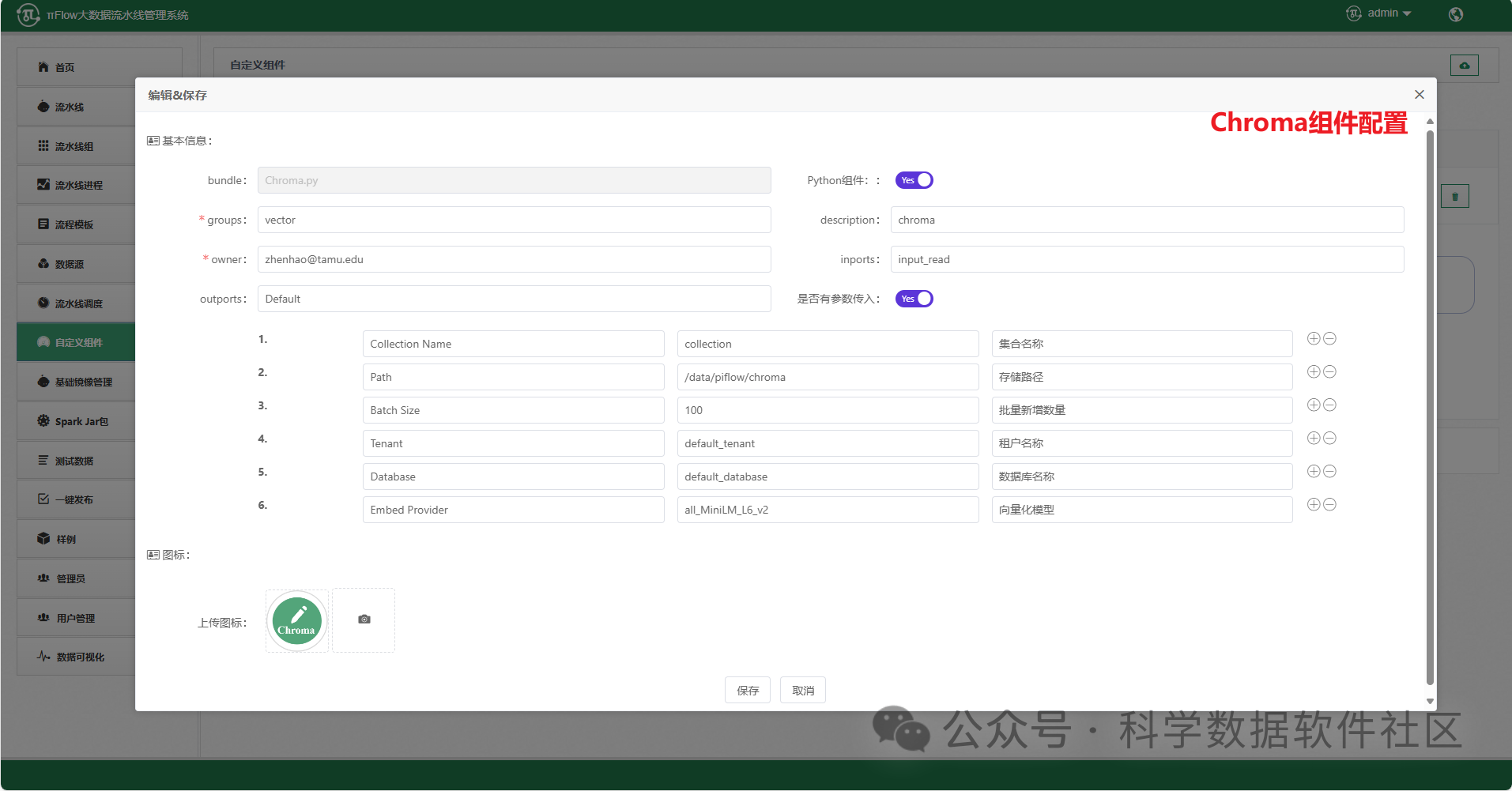
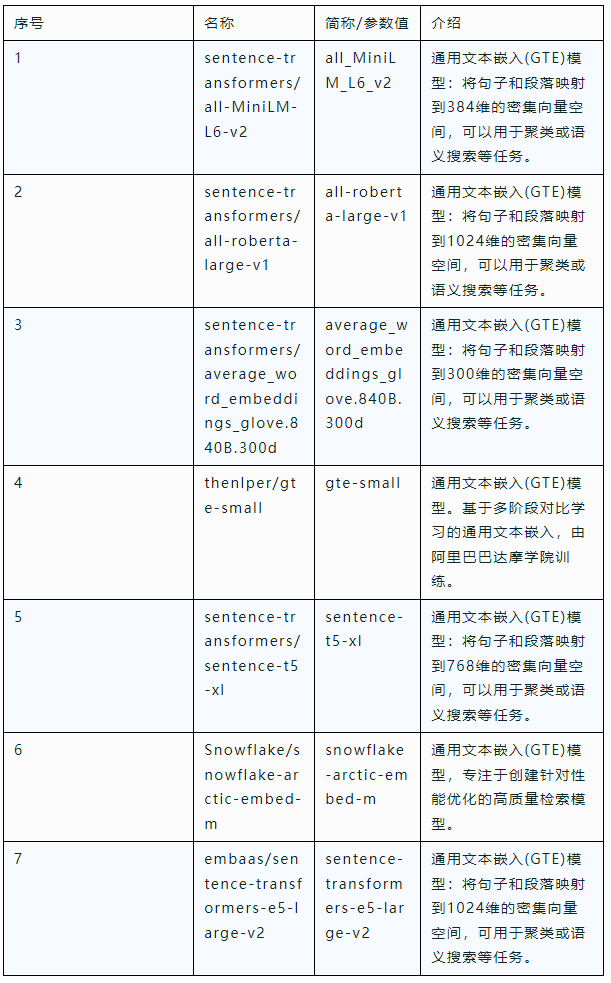
其中,Embed Provider为抽取出来的嵌入模型参数,目前集成了7个模型,支持自定义扩展(源码在https://github.com/cas-bigdatalab/piflow/blob/master/python/embed/embed.zip中的helpers.py),具体信息如下表所示。用户可以自行在hugging face官网下载,也可以用网盘下载(https://pan.quark.cn/s/fc0de5220493),下载后放入/data目录下。