大数据流水线系统πFlow V1.6版本正式发布,本次版本更新包含如下内容:
- 全面适配Spark 3
- 新增TBase读写组件
全面适配Spark 3
全面适配Spark3的πFlow将为大数据处理带来更高效、更灵活的解决方案,助力用户更好地应对大规模数据的挑战。 使用版本:
- scala-version:2.12.18
- spark-version:3.4.0
- hadoop-version:3.3.0
新增TBase读写组件 TBase是腾讯自研的分布式数据库,可以轻松应对亿级数据的存储、分析和查询。集高扩展性、高SQL兼容度、完整的分布式事务支持、多级容灾能力以及多维度资源隔离等能力于一身,采用无共享的集群架构,适用于PB级海量 HTAP 场景。 πFlow通过JDBC方式集成TBase,相关组件为:TbaseRead,TbaseWrite。 Tbase流水线样例配置: 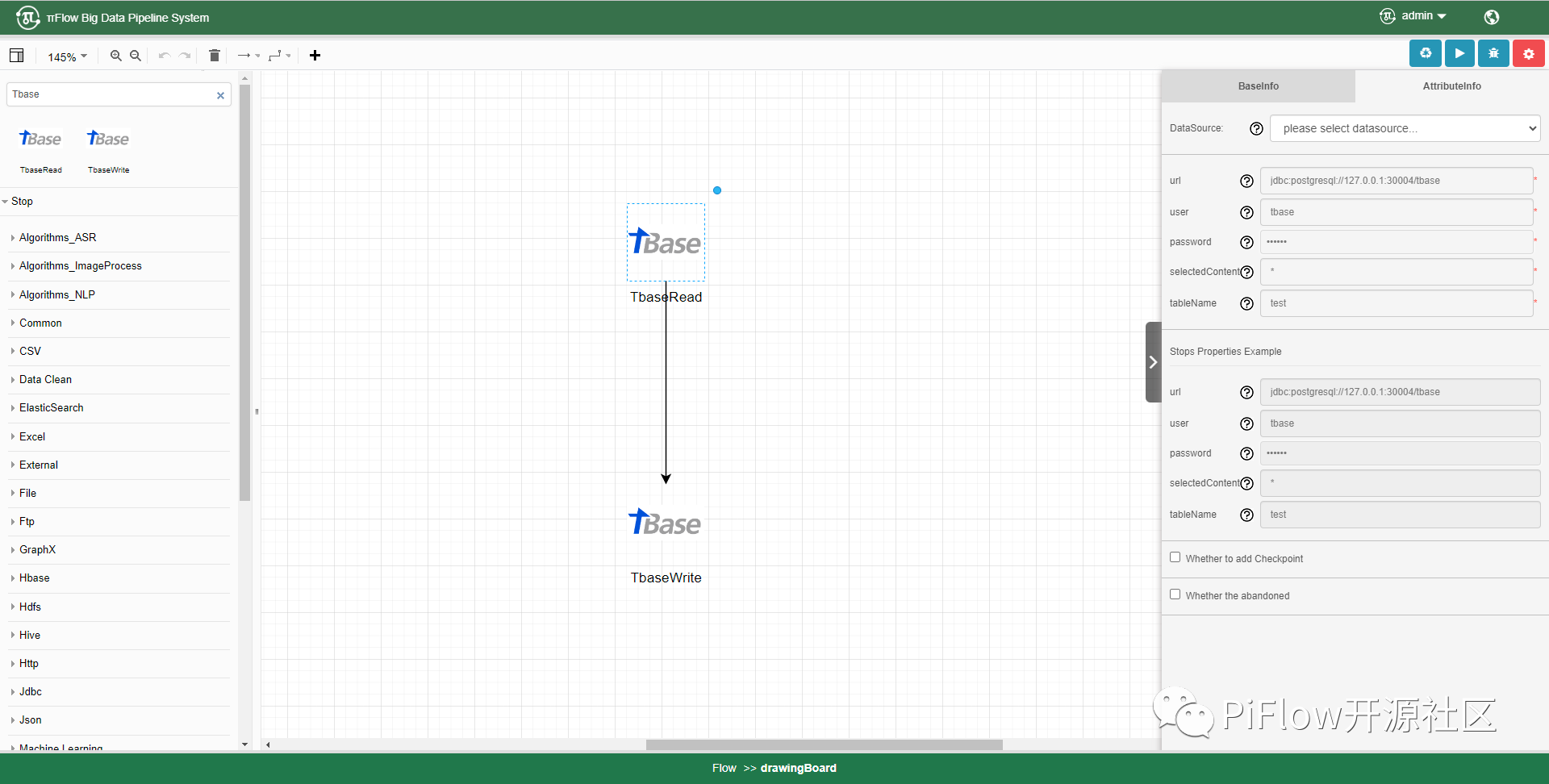
TbaseRead参数说明:
- url:Tbase的数据库连接地址
- user:用户名
- password:密码
- selectedContent:选取字段(*代表全部字段)
- tableName:表名
TbaseWrite参数说明:
- url:Tbase的数据库连接地址
- user:用户名
- password:密码
- dbtable:表名
- saveMode:保存模式,(Append,Overwrite,Ignore)
关于πFlow
πFlow是一个基于分布式计算框架技术开发的大数据流水线处理与调度系统。该系统将大数据采集、清洗、存储与分析进行抽象和组件化开发,以所见即所得、拖拽配置的方式实现大数据处理流程化配置、运行与智能监控。吸引了大批中小企业、院所高校用户,支撑了科技、工业、跨境电商、数据资产管理、医疗健康等领域大量软件工程案例。
联系我们
我们希望通过πFlow技术人员和更多大数据领域的有志之士,一起将πFlow开源社区打造成国内一流的大数据处理开源社区,欢迎你的加入!
官网地址:http://piflow.mulanos.cn/