在国家微生物科学数据中心的新冠病毒数据库(gcCov)建设中,FairStack的PandaDB通过其多元融合能力与自主可控技术体系,成为支撑多源异构数据治理的核心引擎。该系统通过PandaDB的扩展属性图模型,将新冠病毒相关的基因组、文献、专利、抗体等多元异构数据统一整合为关联开放数据(Linked Open Data, LOD),构建起包含超6,00万个实体节点及1,100万组关系的超大规模知识图谱,替代了原先依赖Neo4j的架构。PandaDB基于其异构数据统一查询引擎实现了自研查询语言CypherPlus,不仅兼容国际通用的OpenCypher标准,还能通过插件化架构支持领域数据类型扩展,使科研人员可以灵活定义生物医学场景专属数据类型,显著提升了跨模态数据的挖掘效率。
性能测试表明,针对超100ms的复杂路径查询(如基因组突变关联分析),PandaDB通过分布式优化实现1.5-10倍加速,且系统冷启动预热效率提升突出,基础查询响应时间从300ms级降至60ms级,大幅优化科研交互体验。作为安全可控的国产替代方案,PandaDB在保持对国际语义网标准(如RDF、SPARQL)兼容性的同时,也保留了与LOD生态系统的协作能力。通过从底层存储到上层查询的全链路自主技术体系,既保障了国际科研协作的流畅性,解决了科研数据主权问题,为新冠病毒研究提供了"多元融合、自主先进、无缝替代"的一站式数据基础设施。
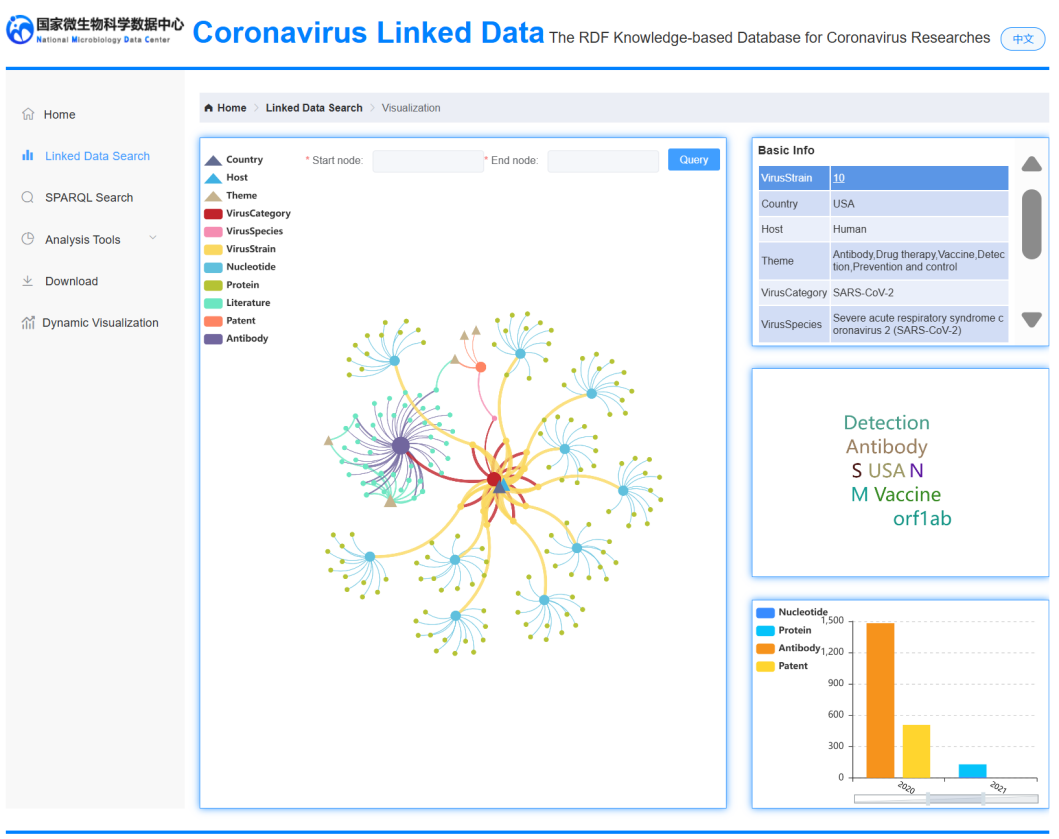
基于PandaDB的新冠病毒数据关联查询