科学地平线(SciHorizon)平台是依托科学领域国家人工智能应用中试基地,由中国科学院计算机网络信息中心牵头建设,旨在构建面向科学智能(AI4Science)方向的“数据+模型”一体化综合评测体系,围绕“AI-Ready科学数据质量”、“大模型科学领域能力”、“科学大模型竞技场”、“科学领域垂类能力”等主题形成了多元化权威评价与基准支撑。 近期,平台完成了系统级迭代升级,在更新学科领域模型榜单的基础上,新增与权威机构共建的科学领域垂类评测榜单。
两大垂直科学领域评测榜单全新上线!
平台推出基因领域和计算机辅助工程领域两大垂直评测板块,旨在形成可复现、可对比的基因领域和计算机辅助工程领域的能力评估环境,推动通用大模型在两个场景下的可靠应用与发展。
1. 基因领域
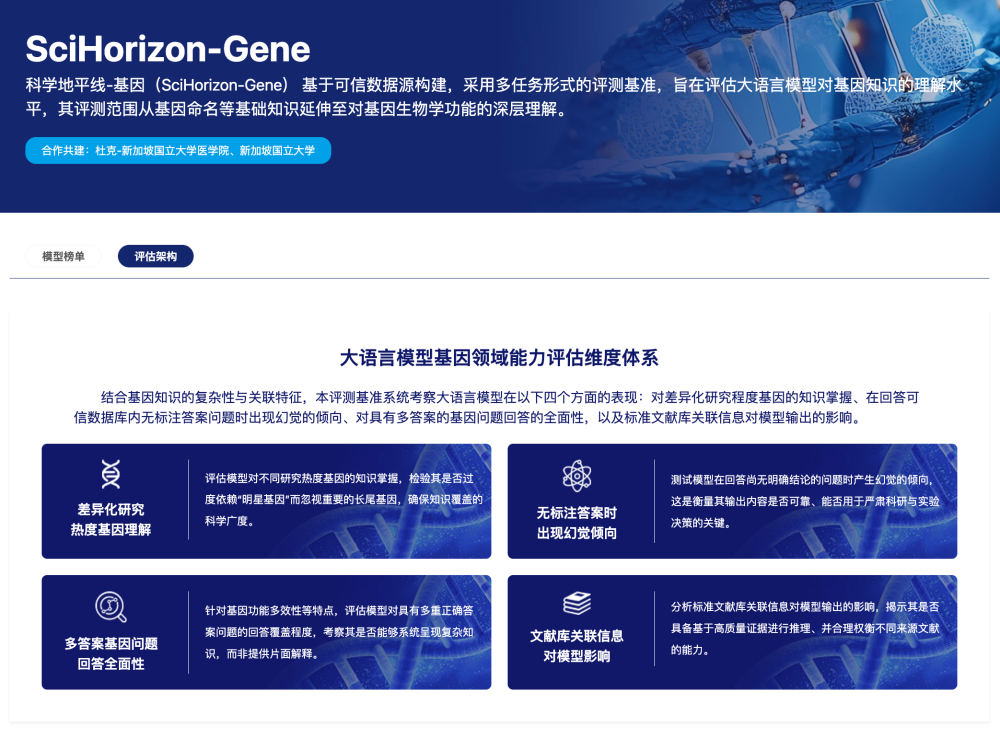
评测体系介绍
科学地平线-基因(SciHorizon-Gene)基于可信数据源构建面向大语言模型的基因知识理解测评基准,旨在评估大语言模型对基因知识的理解水平。结合基因知识的复杂性与关联特征,本评测基准系统重点从四个方面进行考察 :对差异化研究程度基因的知识掌握、在回答可信数据库内无标注答案问题时出现幻觉的倾向、对具有多答案的基因问题回答的全面性,以及标准文献库关联信息对模型输出的影响。
*本榜单为科学地平线平台与杜克-新加坡国立大学医学院等机构共建。
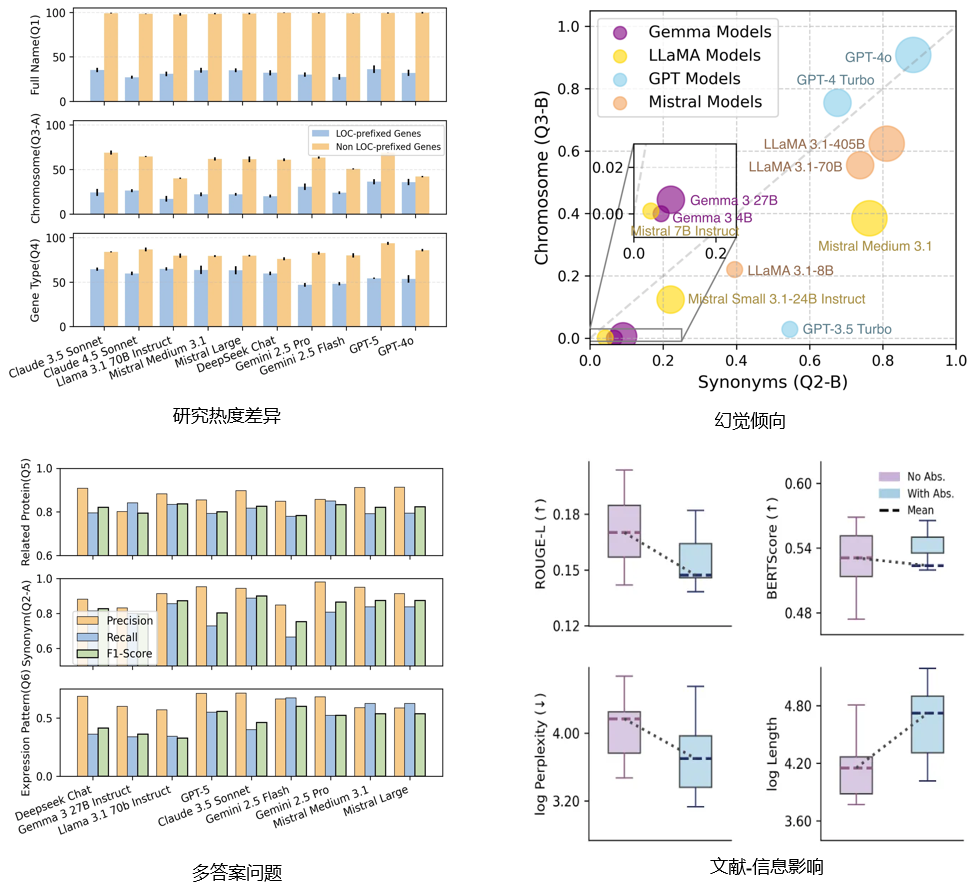
评测结果展示
基准评测了通用领域与生物领域共27个大语言模型,主要结论包括:
- 研究热度差异:评测的大模型在研究更充分的基因问题上通常表现更好;
- 幻觉倾向:参数量更大、能力更强的模型总体上幻觉抵抗能力更高,但不同基因知识类型之间仍存在差异;
- 多答案问题:评测的模型在多答案问题上普遍呈现 Precision 高于 Recall,说明回答更偏保守但相对准确;
- 文献信息影响:提供基因相关文献摘要可降低困惑度,但可能导致回答语义偏离标注内容。
更多关于测评基准的构建,实验设置,结果分析结果欢迎关注我们的技术报告:SciHorizon-Gene: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding (https://www.arxiv.org/abs/2601.12805)
2. 计算机辅助工程领域

评测体系概述
面向计算机辅助工程(CAE)领域结构力学仿真场景,科学地平线-CAE垂类评测构建了分层能力框架,以综合评分为总指标,并设置三项子能力维度:
- L1(知识记忆):衡量模型对结构力学/CAE相关知识的记忆与掌握水平;
- L2(问题求解):衡量模型对工程问题的分析、推导与求解能力;
- L3(仿真应用):衡量模型在仿真应用相关任务中的综合表现。
*本榜单为科学地平线平台与中物院高性能数值模拟软件中心等机构共建。
评测结果展示
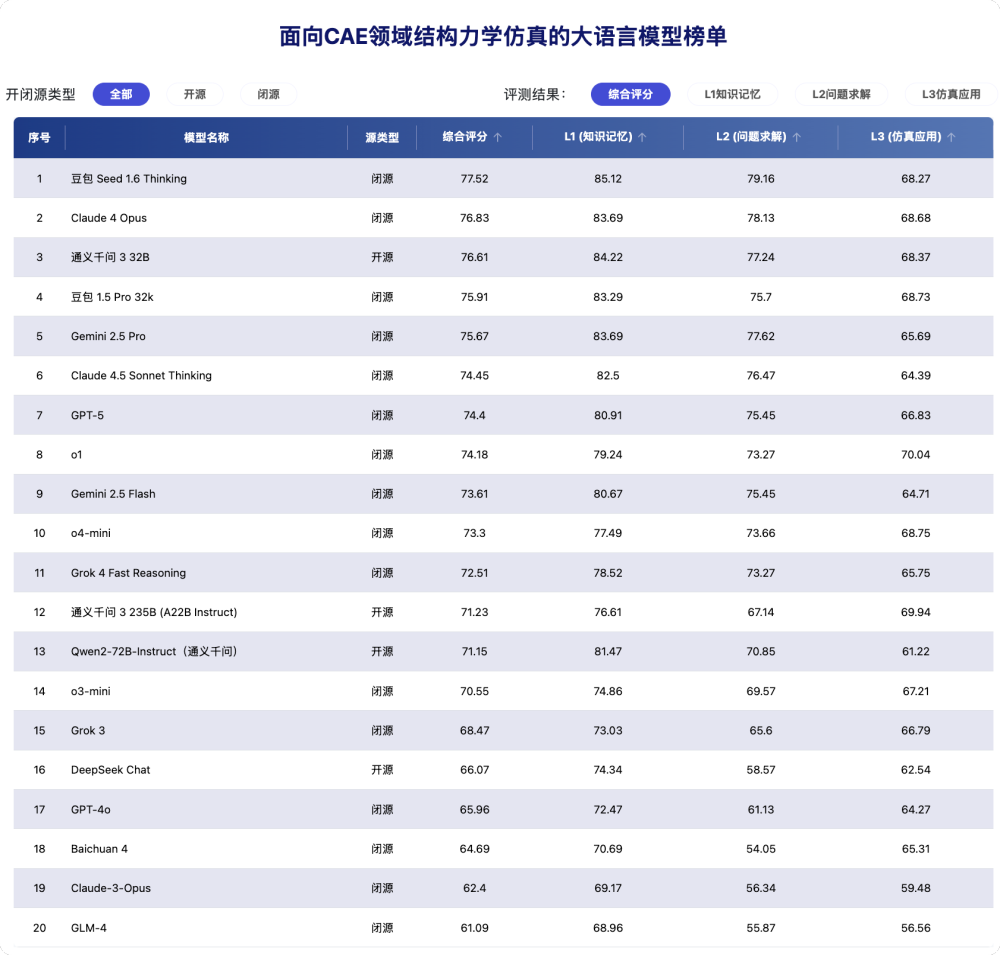
本期榜单共纳入 20 个模型。
综合评分方面:
- 豆包 Seed 1.6 Thinking(77.52)位居第一,在 L1(85.12)与 L2(79.16)两项上均为全榜最高,体现出突出的基础知识与求解能力优势。
- Claude 4 Opus(76.83)与 通义千问3 32B(76.61)分列第二、第三,二者综合分差 0.22,竞争非常接近。
- 前五名还包括 豆包 1.5 Pro 32k(75.91)与 Gemini 2.5 Pro(75.67),构成第一梯队。
不同维度下:
- L1(知识记忆)头部较为集中:豆包 Seed 1.6 Thinking(85.12)领先;通义千问3 32B(84.22)紧随;Claude 4 Opus 与 Gemini 2.5 Pro(均为 83.69)表现同样突出。
- L2(问题求解) 区分度更强:豆包 Seed 1.6 Thinking(79.16)居首;Claude 4 Opus(78.13)与 Gemini 2.5 Pro(77.62)处于高位,通义千问3 32B(77.24)紧随其后 。
- L3(仿真应用) 排名出现分化: o1(70.04)在 L3 维度取得全榜最高分,通义千问3 235B(A22B Instruct,69.94)位列第二。该结果表明,综合排名靠前并不必然意味着在仿真应用(L3)维度同样领先。
更多关于测评基准的构建,实验设置,结果分析结果欢迎关注我们的论文:CAE-Bench: 面向结构力学仿真的大语言模型评估基准 (http://www.jfdc.cnic.cn/CN/Y2025/V7/I4/155)
学科领域模型榜单更新!
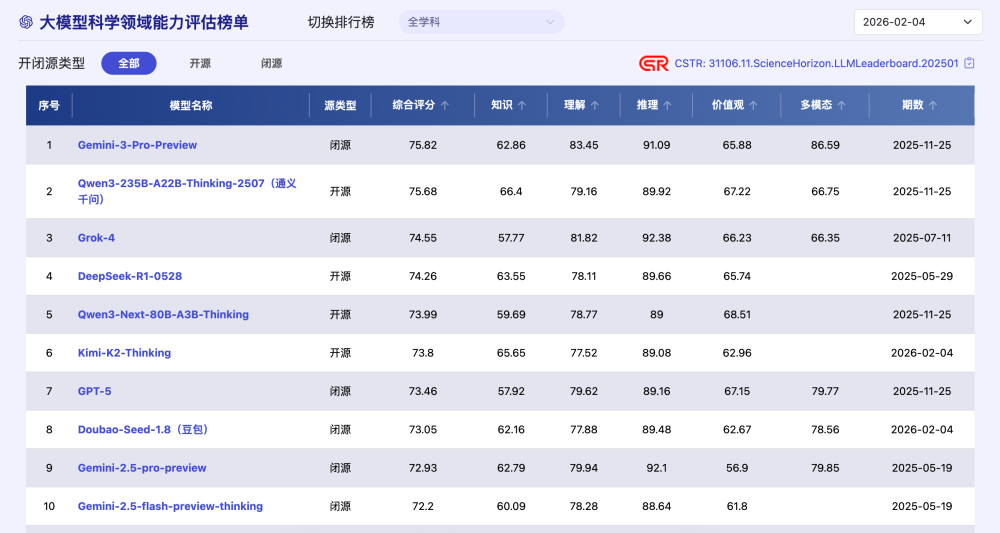
在模型侧,平台已对近期发布的 Kimi-K2-Thinking、Doubao-Seed-1.8 等主流模型开展对比评估,为科研用户提供更具参考价值的横向结果。截至目前,Gemini-3-Pro-Preview 在全学科综合榜单中暂列第一(综合评分 75.82),整体优势仍较为突出。本期新评测的两大国产模型也表现不俗:Kimi-K2-Thinking(73.80)排名第6,优势在知识(65.65),推理(89.08)也保持较强;Doubao-Seed-1.8(73.05)排名第8,推理能力(89.48)优秀,同时多模态成绩(78.56)显示其在多模态能力维度具备一定竞争力。
预告:科学数据评价AI智能体即将发布!
在高质量科学数据的AI就绪度(AI Readiness)评测方面,平台已联合国家空间科学数据中心、国家青藏高原科学数据中心等多家单位,累计发布三期高质量科学数据榜单。下一步,平台将推出面向科学数据评价的AI智能体,进一步优化针对科学数据AI就绪度的评测体系与智能化评测工具。敬请期待!
平台和榜单链接如下
科学地平线平台官网:https://www.scihorizon.cn(文末点击阅读原文可直达)
模型侧榜单地址:https://www.scihorizon.cn/modelList
数据侧榜单地址:https://www.scihorizon.cn/dataList
基因领域榜单地址:https://www.scihorizon.cn/verticalCategory/SciHorizonGene
计算机辅助工程领域榜单地址:https://www.scihorizon.cn/verticalCategory/CAEBench
联系邮箱:scihorizon@cnic.cn
背景介绍
科学地平线(SciHorizon)平台是依托科学领域国家人工智能应用中试基地,由中国科学院计算机网络信息中心牵头建设,专注于面向科学领域的高质量数据与人工智能大模型的评价与应用研究。平台牵头建设单位具有国家认证认可监督管理委员会(CNCA)批准的认证服务机构资质,是我国首个获批的科学数据应用和服务第三方认证机构,是国际数据委员会(CODATA)中国全国委员会秘书处依托单位。核心项目团队在科学数据、人工智能领域拥有丰富的科研和标准研发经验,在Nature Communications、Nature Cities、IEEE TKDE、ACM TOIS、KDD、SIGIR、WWW、NeurIPS、AAAI、IJCAI等国际顶级学术期刊和会议上发表学术论文200余篇,主持研发了包括IEEE国际标准、科学数据国家标准、可信人工智能和大模型行业标准在内的众多国内外标准。