项目选取国际主流图数据库Neo4j作为对标系统,Neo4j是一个高性能的、基于Java的图数据库,它使用原生图存储和检索技术来高效地管理数据。
在领域数据类型适配和异构数据语义关联查询方面,Neo4j可对异构数据进行元数据级别的关联组织,但其不支持非结构化领域数据进行库内语义提取,需要进行预处理才能实现异构数据关联查询。PandaDB采用的用户自定义类型(UDT)机制,使其能够灵活适配不同的领域数据格式,简化了领域数据的入库、查询操作,对领域用户更加友好,且用户可以在UDT中定义非结构化数据的语义提取操作,所提取的语义是结构化类型,可以与其他结构化数据进行比较运算,从而实现了对异构科学数据的库内语义关联查询。
在复杂多跳查询方面,PandaDB综合采用细粒度属性存储结构、谓词下推、双端遍历策略等查询优化策略,第三方评测验证查询性能较Neo4j(v4.4.19社区版)提升3~6倍以上。评测采用了图数据库的国际通行基准测试LDBC的测试数据集(LDBC SNB,SF=1000,有170亿边、25亿节点),部分LDBC Interactive测试语句。两款系统的测试环境相同,均为配置了双路至强可扩展金牌6230R CPU、376GB DDR4内存、219 TB Raid 5 HDD的单台物理机。测试采用加权加速比Acc对比两款系统的查询性能,计算公式如下:
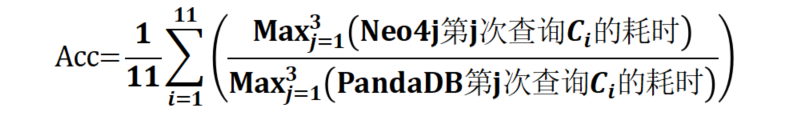
其中,加速比越大表示PandaDB性能优势越明显,为1表示查询性能相同。
如表 9和图1所示,测试结果表明PandaDB相较于Neo4j的加权平均加速比是4.68。其中图 30的横坐标为查询语句编号,纵坐标为查询语句的耗时(单位:秒)。
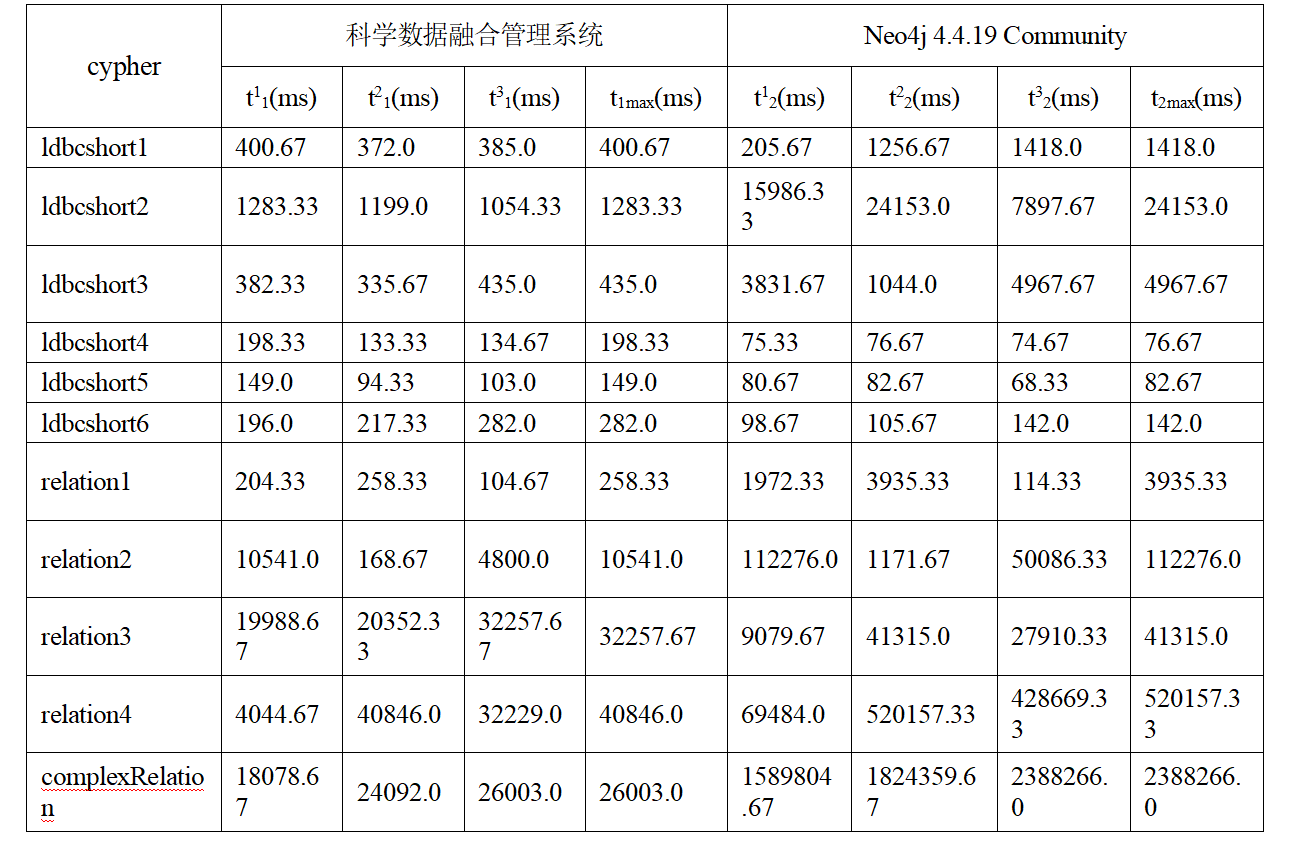
表1 PandaDB与Neo4j查询性能对比
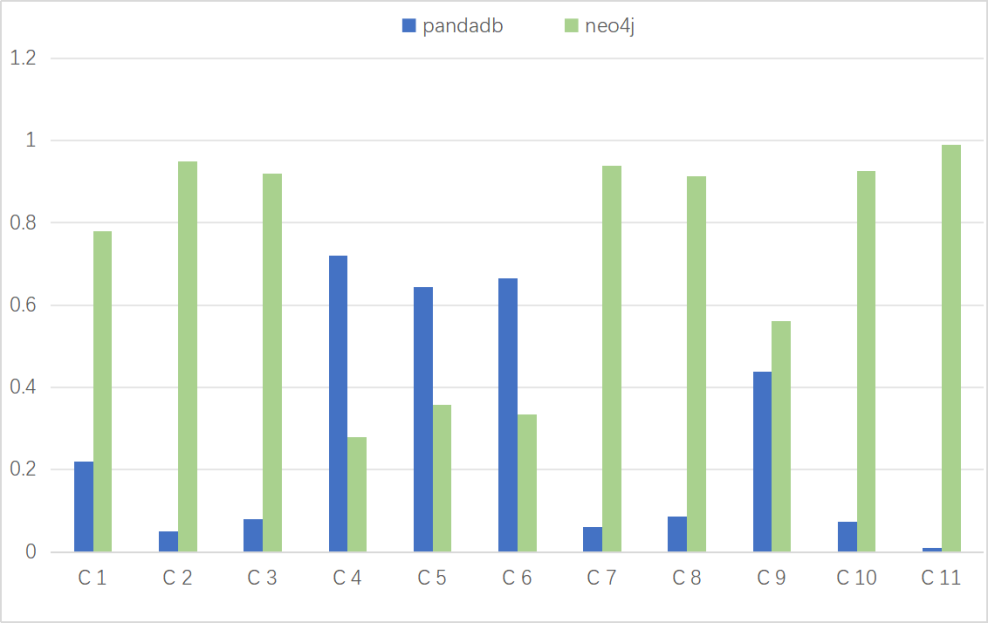
图1 PandaDB与Neo4j查询性能对比图
此外,在开源许可协议方面,Neo4j社区版采用了强传染性的GPLv3开源协议,此协议要求衍生产品必须公开源代码,而PandaDB采用了更宽松的Apache 2.0开源协议,有利于各领域数据中心发展自主核心技术。